Publications
Counterfactual explanations: Can you get to the “ground truth” of black box decision making?
In 2014, Amazon developed a computer program to screen the résumés of job applicants. Applicants were scored based on a point system ranging from 1 to 5. A score of 1 meant they were not suitable for the job, whereas 5 indicated they were very suitable. It was quickly discovered that this algorithm was biased towards male applicants, so Amazon stopped using it. However, it is very likely that Amazon or other companies will use decision algorithms like this in the future.
This article examines black box algorithms and different types of feature highlighting explanations, in particular the counterfactual explanation method. By using an example legal scenario, I examine whether the counterfactual method is capable of explaining an outcome. I call this finding the “ground truth” or the true reason behind an algorithm providing a certain output. There must be something in the algorithm that is the direct cause of the model to produce an outcome like, for example, rejecting a job applicant. This could be in the form of one single feature being attributed a certain value, but it could also be a combination of features that caused the model to give a certain output.
Can we trust algorithms we don’t understand?
If algorithms are going to make important decisions in our lives, we must trust them. In order to establish trust, we need to understand how they work. That is why we need methods of explaining these complex algorithms. Algorithmic accountability—the idea that companies must be responsible for the outcomes resulting from the use of algorithms—depends on understanding how the algorithms operate.
Companies such as Amazon should demonstrate accountability by addressing any bias in their algorithms and fix it. Furthermore, someone who is negatively affected by such algorithms has the right to know what the decision was based on. It is required by law that companies are able to explain how their algorithm came to its decision. This is called algorithmic transparency. When users understand how an algorithm arrived at a certain decision, it provides them with an opportunity to oppose the decision.
For the much of the remainder of the article, I will use the following scenario to aid my examination of explaining outcomes of algorithms:
Imagine a future where decision algorithms like this are widely used. You apply for a job at a company, for example Amazon, who use a decision algorithm to review resumes. You are fairly confident that you are able to get the job. You have the required qualifications, sufficient years of experience and a positive referral from your previous manager. But, the algorithm decides that you’re not suitable for the job. You feel like you have been treated unfairly and you decide to sue the company. GDPR, the EU’s General Data Protection Regulation, states that individuals have a right to an explanation, so that is what you demand.
It is likely—looking at current trends in machine learning—that this imaginary company would use a black box algorithm as the decision-making algorithm. In this case, I anticipate that they would provide a form of feature highlighting explanation as their answer.
What is a black box decision algorithm?
Decision algorithms make decisions based on large amounts of data. You have probably encountered them before, for example on social media. The content that is recommended to you on Youtube, Netflix or Instagram is decided by an algorithm.
These algorithms are deep learning models or “neural networks”. They are fed input data, which is then processed by many layers of units or “neurons”. The connections between these units have a certain weight that determines how the data is transformed as it passes through the network. At the end of the network, the model produces an output. The weights of the connections between units are not determined by people, but are the result of a training process. There are various ways of training a neural network, but in essence it involves learning from many example input-output pairs by solving an optimisation problem incrementally.

(Source).
The inside of the model is essentially a “black box”, ie no person can fully understand how the algorithm came to its decision. There are simply too many units, too many weights and too many steps in the training process to keep track of. Models that are not easily understandable by people are also called “uninterpretable”. On the other hand, models that are easily understood by people are called “interpretable” models. These models could be in the form of linear models, decision trees, or falling rule lists.
How do machines learn bias?
Even though the weights of the model are trained according to an optimisation problem and not by people, this does not mean that the model can’t be biased. If the data that the model is trained on is biased, the model will be biased as well. As the model is trained, its outcomes are measured relative to the training data. If this data is biased, the model will “learn” to be biased.
Amazon’s recruitment algorithm exemplifies this. It exhibited gender bias because it was trained on biased data. Of course an algorithm doesn’t understand the concepts of male and female. The algorithm was trained on data from previous job applications. Since these applicants were mostly male, the algorithm learned to be biased toward men.
Feature highlighting explanations
The counterfactual explanation method is a type of feature highlighting method. Feature highlighting explanations point out the variables that had the biggest influence on the outcome of the model. There are many other feature highlighting methods, for example XRAI and LIME. XRAI is an image processing algorithm that highlights the regions of an image that had the biggest impact on the classification of that image.

(Source).
LIME stands for Local Interpretable Model-agnostic Explanations. LIME explains black boxes by approximating them with an interpretable model on a local basis. By locally I mean that LIME only explains one prediction at a time. The interpretable model that is used to approximate the actual model could be in the form of a linear model or a decision tree.
When generating an explanation, LIME generates a number of interpretable models such as decision trees. Each one of them is trained on a variation of the original input data. These alternative input datasets are created by leaving out specific features of the original input data on each attempt. For example, if the original input were a text, the features would be in the form of words. The alternative inputs would consist of the same text but omitting a few words. The words to be left out are chosen randomly. Different words would be left out in different alternative inputs. This way it becomes clear what words (features) had the biggest impact on the model outcome. If the approximated model gives the same output as the original model you know that the features that were left out in that alternative input did not have an impact on the model output. If the output of the approximated model varies from the original output you know that the features that were left out in the alternative input were significant (more information on LIME here and here).
Back to our scenario…
The company that you applied to work at explains their decision algorithm in court using LIME. The results show that the features that had the biggest impact on the outcome were your age and the years of experience on your CV. But it doesn’t feel right to you to explain a model by explaining an approximation of it. Because the explanation is based on an approximated model, it doesn’t concern the exact same feature space as the original model, so how can you be sure that the explanation for the approximated model also explains the black box that lies underneath? The ground truth of the approximated model might not be the same ground truth of the actual model. You are not satisfied and demand another explanation using a different method.
Counterfactual explanations
The counterfactual or CF explanation method is a type of feature highlighting method developed by Wachter et al. CF explanations don’t just point out what features had the most influence on the decision of the algorithm, they also suggest in what direction the features have to change in order to change the decision.
Counterfactuals use alternative values of features of a data subject. They are a possible way a feature of a subject could be. Going back to the recruitment algorithm that Amazon used in the past, let’s say an applicant has 4 years of work experience. A counterfactual value of the variable “work experience” could be 5. CF explanations show what the outcome of the model would have been if the input features would have been different. For example, a CF explanation would point out to a rejected applicant with 3 years’ previous retail experience that they would have been hired if they had 5 years of experience. The counterfactual method does not require opening the black box. It is only concerned with the model inputs and outputs, the units inside the neural network do not need to be considered.


How does a counterfactual explanation work?
The search for the most influential features involves solving an optimisation problem using gradient descent. This particular formulation of the optimisation problem selects an optimal CF explanation, based on what the desired outcome is:
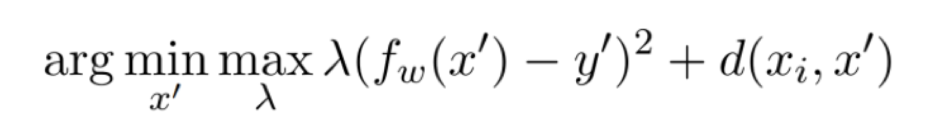
The first term calculates the squared distance between the outcome of the counterfactual model, fw(x’), and the desired outcome, y’. The counterfactual model is created by changing the value of only one feature. So it is not the case that multiple features vary from their original value in counterfactual examples. The desired outcome is what the user wants the decision of the algorithm to be. As mentioned before, Amazon’s recruitment algorithm judged applicants based on a point system. The desired outcome in this case would be 5 points. The distance represents how close the counterfactual outcome is to the original outcome.
The second term calculates the distance between the counterfactual input, x’, and the original input, xi. For example, if the original input for the feature “age” were 33, the counterfactual input could be 32. A small distance represents a small change in the feature value.
The first and second terms are added and then multiplied by λ. Beforehand the value of λ is decided by the model developers and is based on what they want the explanation to emphasise the most. A high value of λ makes the formula more likely to select a counterfactual model whose outcome is close to the desired outcome. A low value of λ puts more emphasis on minimising the distance between the counterfactuals and the original input and therefore makes the formula more likely to select a model that requires very little change of feature values. This formula is executed in a number of repeating steps. The value of λ is initially set to a low value. Then a counterfactual is randomly generated and is used as a starting point for optimising the function. This step is repeated, while increasing the value λ each time, until the counterfactual explanations that are generated pass a certain tolerance threshold related to the distance of the counterfactuals and the original value (more information).
There are a couple of questions to consider when deciding what features to focus on, and thus what the value of λ should be. This value has influence on whether the explanation gets to the ground truth of the decision. Should the explanation focus on features that have to be changed drastically in order for the model output to be changed? Or should they suggest changes in features that only need to change marginally? When CF explanations follow the first approach and focus on the most outlying features, you could argue that they will indicate clearly to subjects what features had the biggest impact on the output. However, this doesn’t have to be the case, because models don’t consider the causal relationships between features. It could be that features have a certain value because they interact with other features.
The ground truth of the decision might lay in the feature that the outlying feature is dependent on. Focusing on the outlying features will then not unearth the ground truth of the decision. This is why it could be preferable for CF explanations to follow the second approach and only suggest close possible realities. These features are most likely easy to change. However, if the decision model happens to be biased and gender or race had a major impact on the output, the users as well as the developers will remain ignorant to this. Let’s say the model rejected an applicant based on their postal code, according to the explanation. But postal codes are related to race. So the ground truth reason that this applicant was rejected was their race and the explanation did not show this. It considered the features in isolation and not in interaction. So the second approach might not get to the ground truth either.
Wachter et al argue that incorporating causal relationships between features is unnecessary. Their counterfactual generating algorithm assumes that features are independent of each other. According to them the main focus of counterfactual explanations is to provide users with suggestions as to how to change the outcome of the model. It seems as if they are not particularly focused on getting to the ground truth of the decision of a model. Because that is their main focus, assuming all features to be independent is sufficient. Including causal relationships between features would only make the explanations harder to understand for decision subjects.
To arrive at the ground truth of a decision, causal relationships need to be considered. Features in the real world are not always independent, so ignoring that would be inaccurate and unfair. Fairness is a term used to describe machine learning algorithms. An algorithm is fair if it does not base its outcomes on certain “protected variables”. These variables usually concern age, gender, nationality or sexuality. So these variables should never be the ground truth reason for an algorithm to give a certain output. Incorporating causal relationships between variables can be realised using causal inference techniques.
The court agreed with your demand and the company has provided you with a counterfactual explanation. The model came up with the following suggestion: your chances of getting the job would increase if you had more years of experience. However, you are still not satisfied. It might be true that you are relatively inexperienced, but the referral from your previous employer is very positive. It seems reasonable to you that the quality of your experience as well as the quantity should be taken into account. You want to know who decides what features to focus on when coming up with the explanation.
Decision makers can decide what features the CF explanation will suggest users to change. Algorithm developers can use the counterfactual method to make the explanation favourable to them. Counterfactual explanations therefore pose the risk of handing over a lot of power to the decision maker. For example, an algorithm might be biased towards race, and by carefully choosing the λ value developers can make sure the explanation will not point this out.
Changing the inputs of the CF model in such a way that the outcome is fitting to the developers and so hiding the true decision process, is a form of gaming. Gaming is a way of manipulating a system without breaking any rules, but still making the outcome of the system favourable to you. For example, different CF explanations of a decision algorithm will show different features that had an impact on the model outcome. Developers of a biased decision algorithm might choose the particular explanation that does not point out the features that suggest the model is biased. They will choose the explanation that gives the postal code as the reason why someone isn’t suitable for the job, when in fact their race is the true reason.
In order to prevent decision makers from hiding the true decision process, users could be given multiple counterfactual explanations. This way the subjects could choose for themselves which one fits best with their life.
The following formula generates a set of different CF explanations:
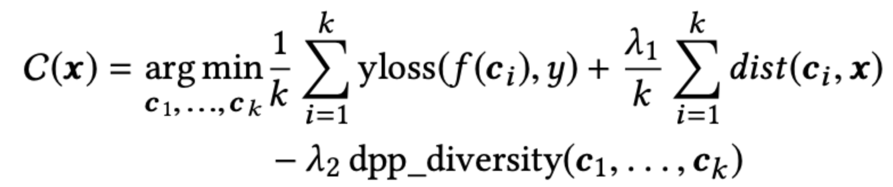
The output is a set of counterfactual examples, denoted by C. In the first term of the formula, yloss, the difference between the desired outcome, y, and the outcome of the model when using a particular counterfactual as input, f(ci), is minimised.
The second term calculates dist—the distance or “proximity” between a counterfactual feature, ci, and an original input feature, x. If a counterfactual feature differs only slightly from the original feature, it is probably easy for a subject to change the original feature to the counterfactual feature. The proximity of a set of k counterfactuals, forming a complete counterfactual explanation, is the average proximity of each feature individually.
The last term, dpp_diversity, calculates how diverse the different CF explanations are. DPP stands for determinantal point process. A DPP generates subsets of data and assigns to each subset a probability. In this case, the subsets of data would consist of different counterfactual situations. The probability of subsets with diverse data points is higher than the probability of subsets with similar items. In other words, subsets with diverse counterfactuals end up with a higher probability, so subjects end up with a diverse set of counterfactual explanations to choose from (more information).
Black box vs interpretable models: finding the ground truth
As mentioned before, interpretable models are models that are easily comprehensible to people. Considering the challenges described above concerning explanation methods of uninterpretable black box models, the question arises: even if programmers succeed in developing the best explanation method, will they come up with the ground truth even then? Would it be better to use interpretable models instead?
The problem lies in the black box model of the decision algorithm, not in the explanation method. The CF method never claimed to be able to make neural networks interpretable. It might just not be reasonable to expect any explanation method to do so in an understandable way.
So in a way, CF explanations offer companies who use black box models a cheap way out. If we accept CF explanations, we are accepting explanations that don’t get to the ground truth of why an algorithm made a certain decision. By using them, developers don’t have to understand the actual inner workings of their models. This is dangerous if these models make impactful decisions on peoples’ lives.
Besides excusing developers from deeply understanding their complex models, CF explanations add another layer of complexity on top of those models. As discussed before, it is difficult to know if the CF explanations actually get to the ground truth of the decision making process. So now developers have to understand two systems instead of one. They need an understanding of the complex CF method in order to know if the explanation that method provides accurately explains the model they were trying to understand in the first place.
It can even be argued that all feature highlighting explanation methods are insufficient. Highlighting features that impacted the model outcome does not explain how they did that.
Another option is to use interpretable algorithms instead of black box models. Interpretable algorithms are easily comprehensible to people, so all the problems I just described become irrelevant. There is this conception that in order to explain complex systems, you need a complex model. It seems that the more complicated and uninterpretable models are, the better they are at accurately explaining algorithms. In most situations, this is not the case.
Currently opinions are divided about which approach is better, because there are some downsides to interpretable models as well. Firstly, black box models protect the companies that use them. Interpretable models would give away company secrets by showing the internal structure of the model. Furthermore, interpretability is domain-specific, this means that not all algorithms can be made interpretable in the same way. Therefore it takes more effort to develop interpretable ML models. They involve solving difficult computational problems that not a lot of people currently are able to do (ibid).
It seems hard to justify using explanation methods of black box decision models without knowing fully if these explanations get to the ground truth of decisions, because developing interpretable models would take more effort and comes with the risk of losing profit.
This article was written by Julia Boers. Connect with her on LinkedIn.
Get in touch!
Did this article raise some questions or inspire you? Then shoot us an email on c4i@sea.leidenuniv.nl

{kind=link}